Bug #283
ferméAugmentation de l'usage CPU du site
100%
Description
Depuis mardi 25 OU le mercredi 26 avril 2025, on a des problèmes sur le site :
- Uusage CPU du site anormalement élevé (toujours pas réglé)
- Indisponibilités aléatoires (erreur connexion DB)
Mardi 25 avril 2023 :
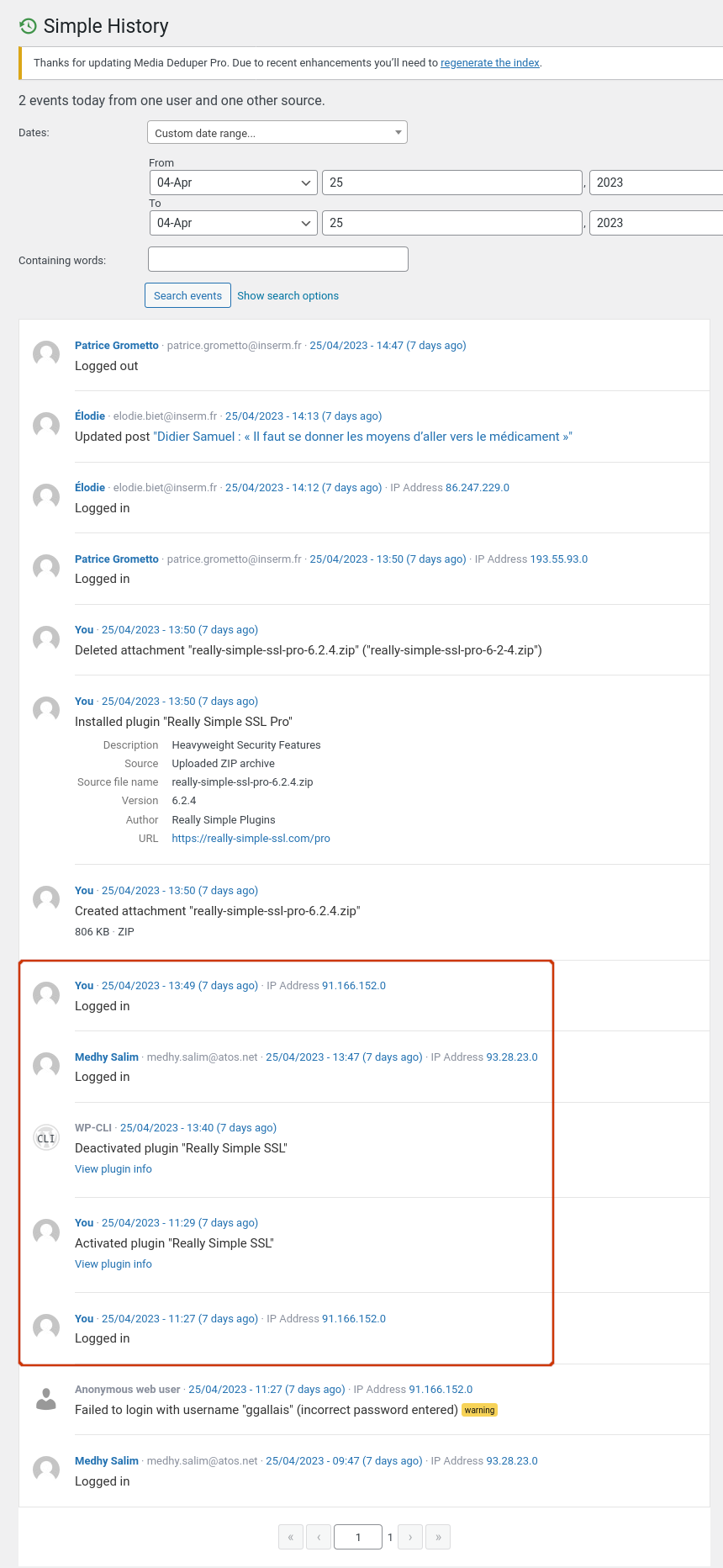
- 12h29 Guillaume installe Really Simple SSL via un script lancé depuis le site web de RS SSL (fonctionnalité d'installation automatique)
- Immédiatement, on perd l'accès au BO du site, mais le front reste fonctionnel
- 13h01 (selon Slack) Guillaume prévient l'équipe fonctionnelle
- 14h13 (selon Teams) Guillaume prévient l'équipe ATOS
- 14h48 (selon Teams) Medhy annonce avoir désactivé le plugin et reseté le .htaccess (source Teams).
- Tout revient à la normale
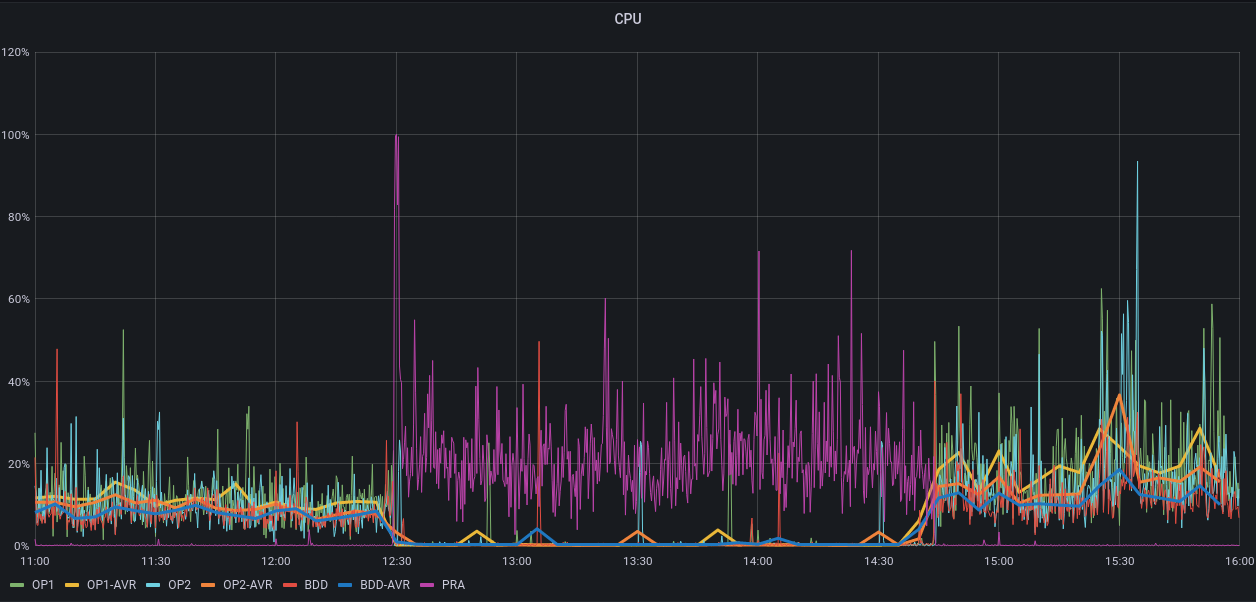
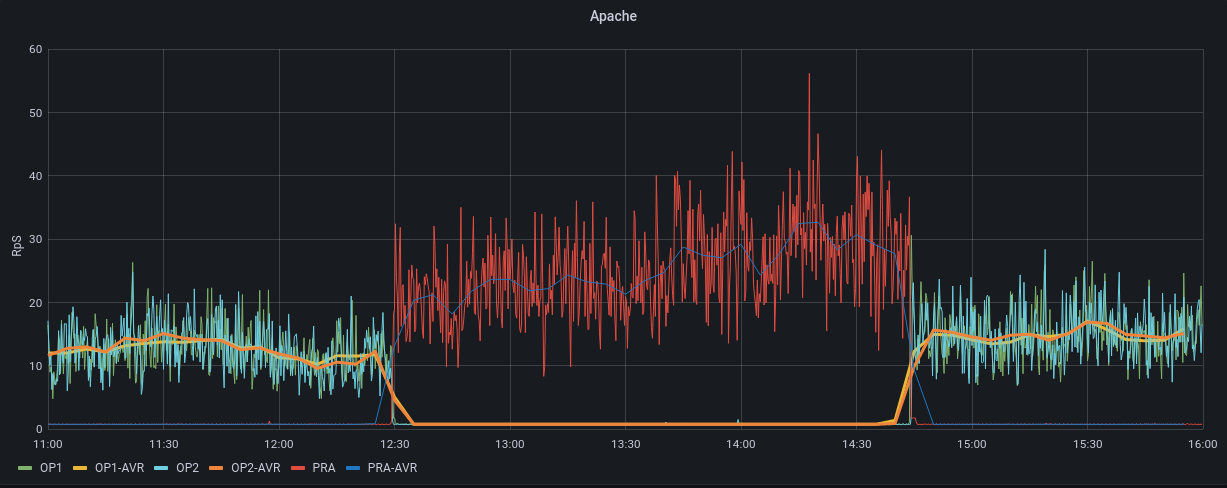
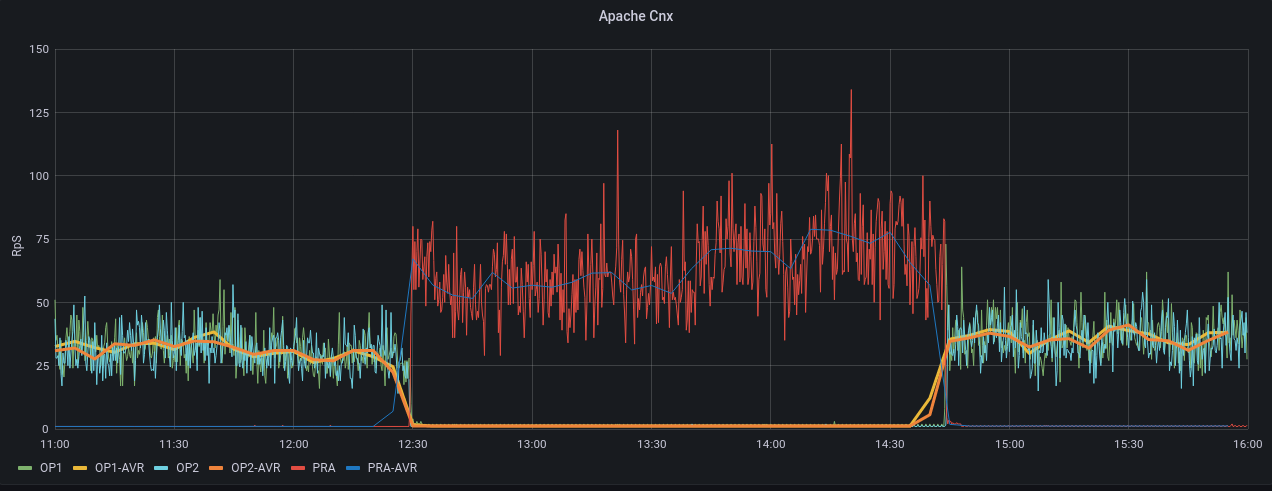
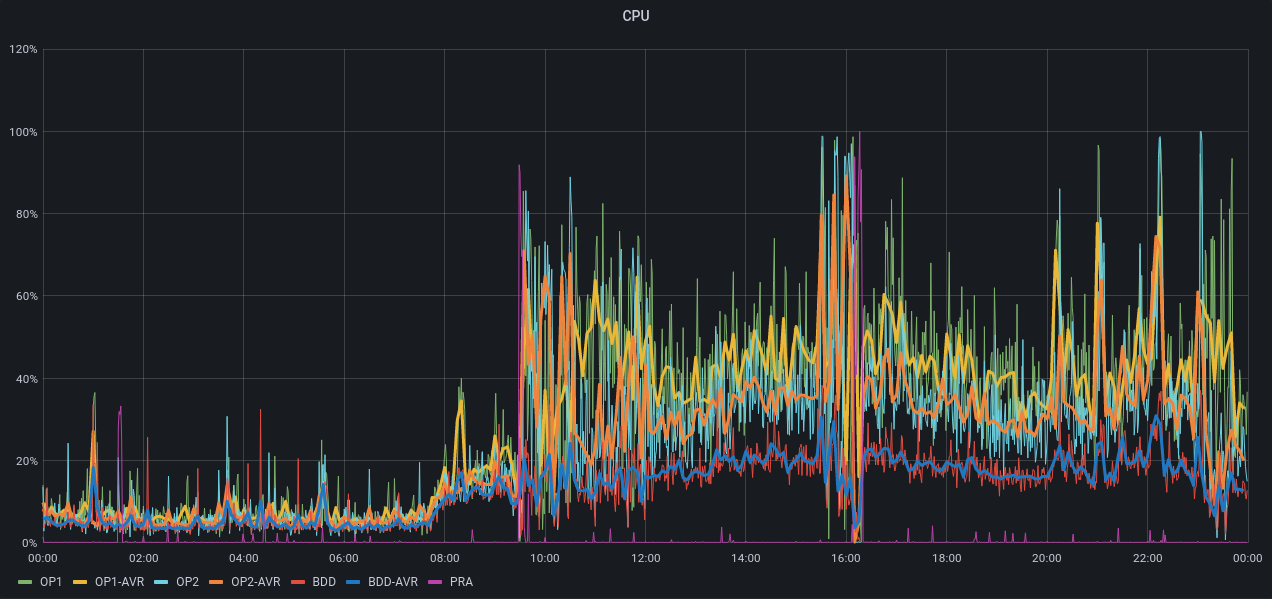
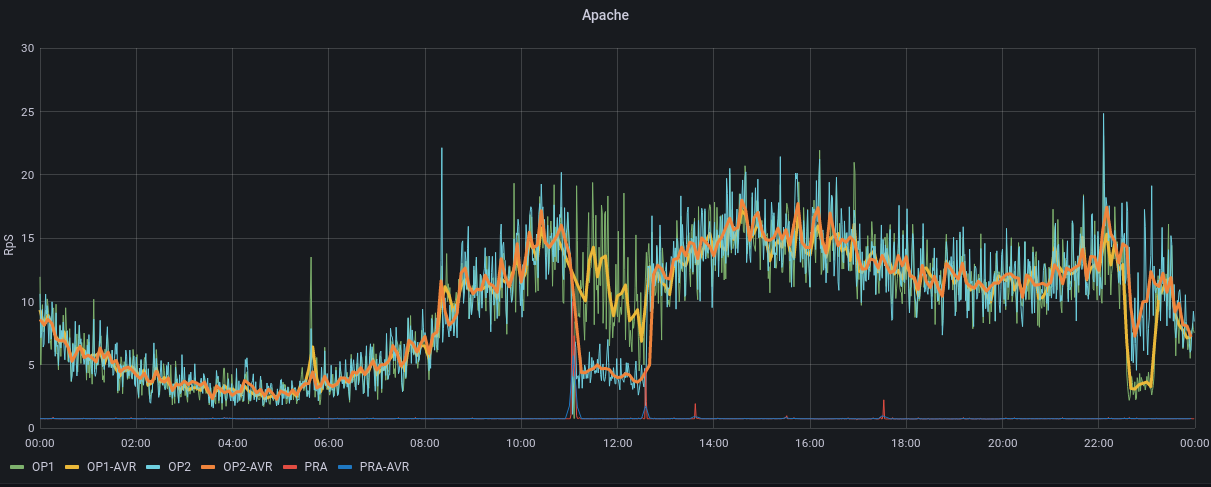
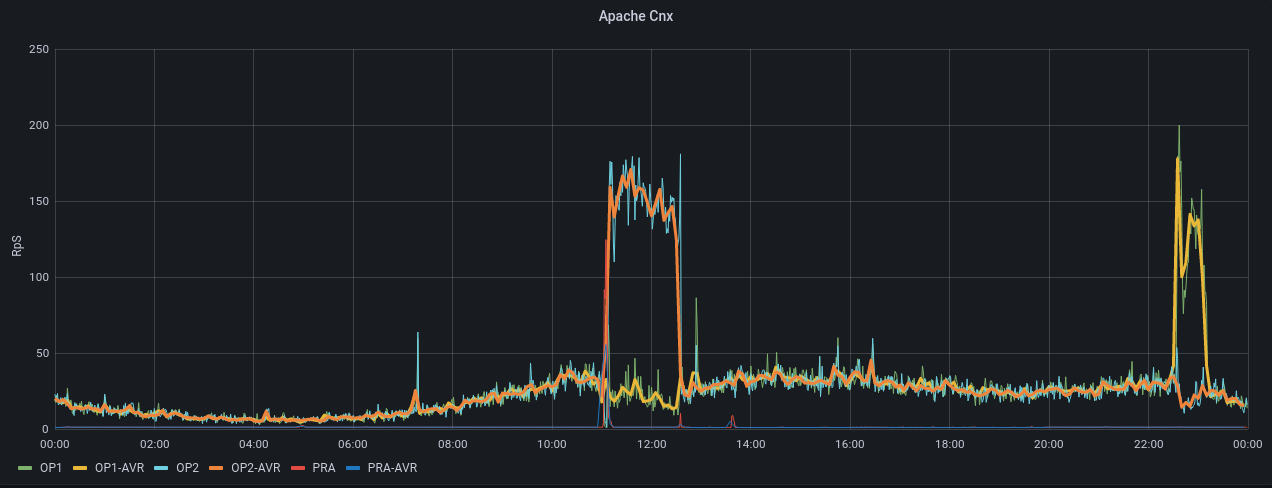
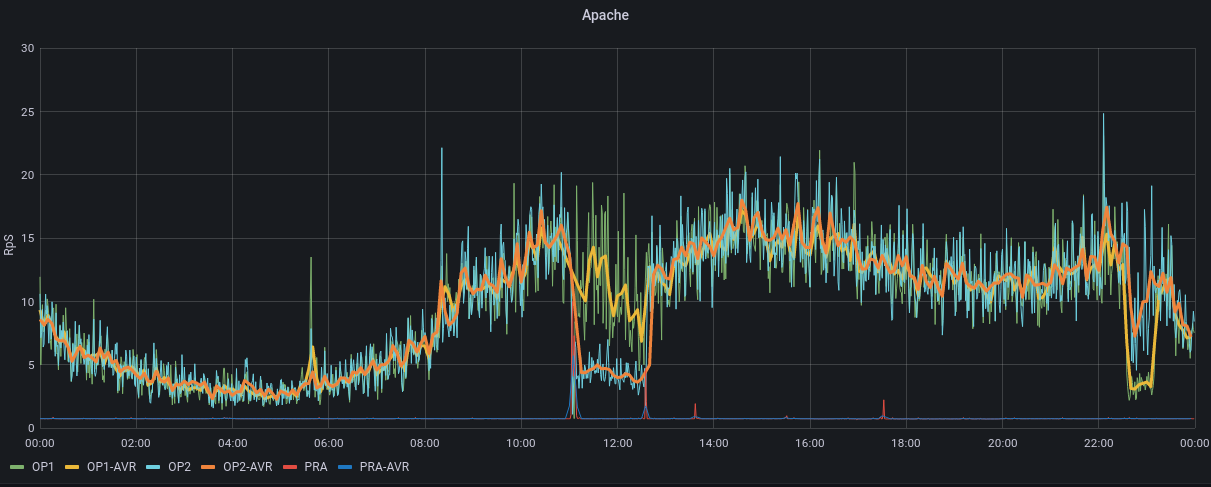
Simple History a logué en BO une partie des actions, mais l'heure du site est décalée. Ça dit que le plugin a été installé à 11h29 et désintallé à 13h40, au lieu de 12h29 et 14h40. Grafana monte bien l'impact CPU, Apache, Apache CNX, Load entre 12h30 et 15h voir PJ.
Mercredi 26 avril 2023 (selon Teams) :
- 9h30 annonce de la fin de MEP du #275
- 10h28 annonce de la perte de la connexion à la BDD en front
- On envisage que ça soit une panne Google (incident ce jour), mais le site de la presse lui est OK
- 12h04 Eddy envoie des infos qui montrent que notre serveur Google n'est PAS affecté par la panne Google
- 15h50 on a encore des erreurs bdd ne prod
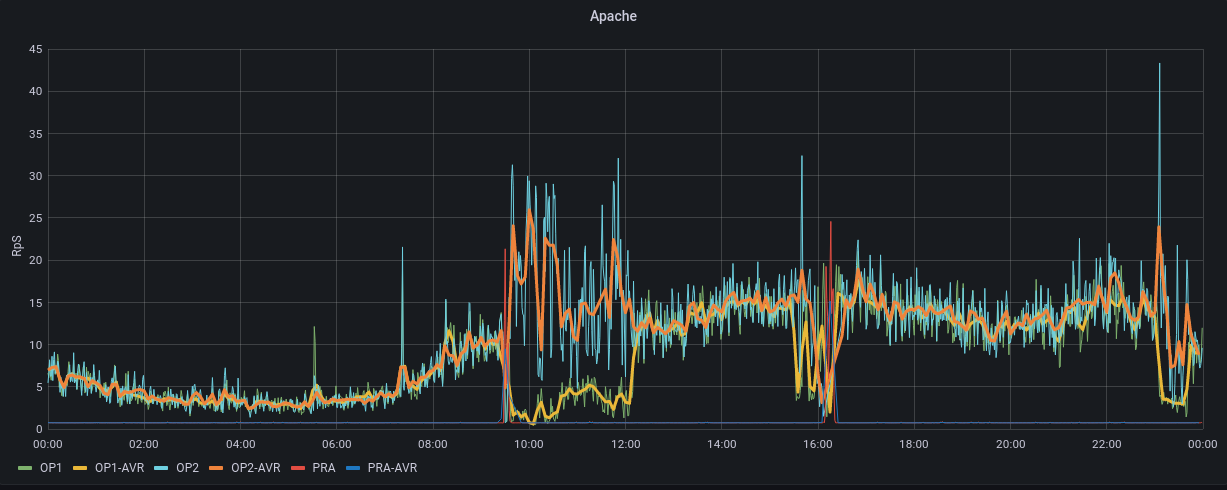
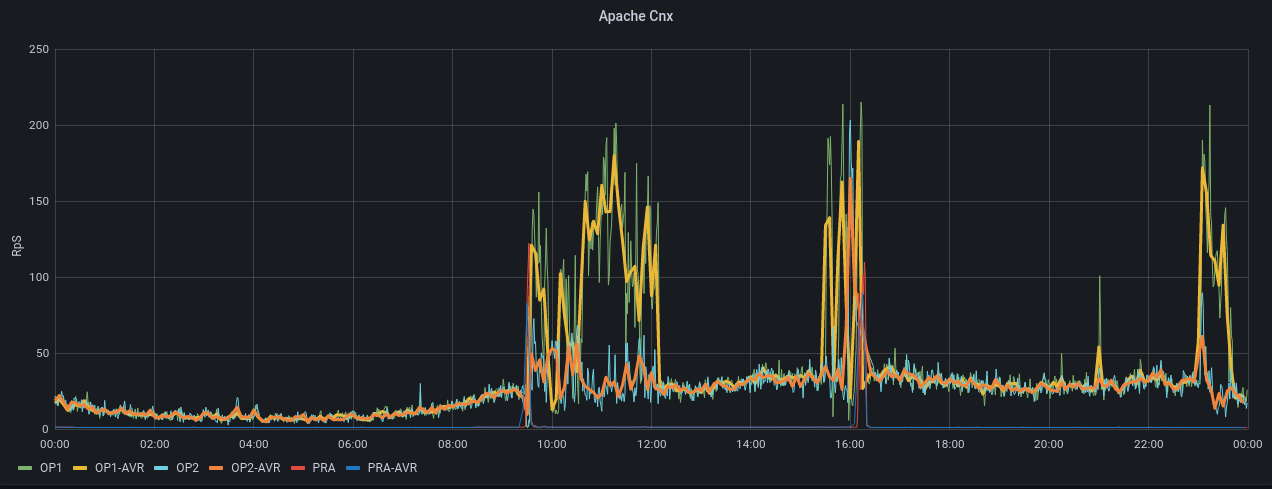
Grafana montre que le site décroche à partir de 9h20, on retrouve aussi un problème vers 16h et un pendant la nuit (voir PJ). Le load montre que l'incident n'a aucune mesure avec la veille : on est à 250 le 26 avril alors qu'on était à 8 au pic du problème du 25 avril.
Jeudi 27 avril 2023 :
- 10h18 Patrice constate que le site va toujours mal (selon grafana)
- 11h07 Medhy annonce avoir rollbacké la MEP de la veille
- 12h36 reboot OP1 OP2 et BDD
Dans Grafana, on voit le CPU, Apache, Apache CNX, et le load réagir au moment du reboot
Vendredi 28 avril 2023 :
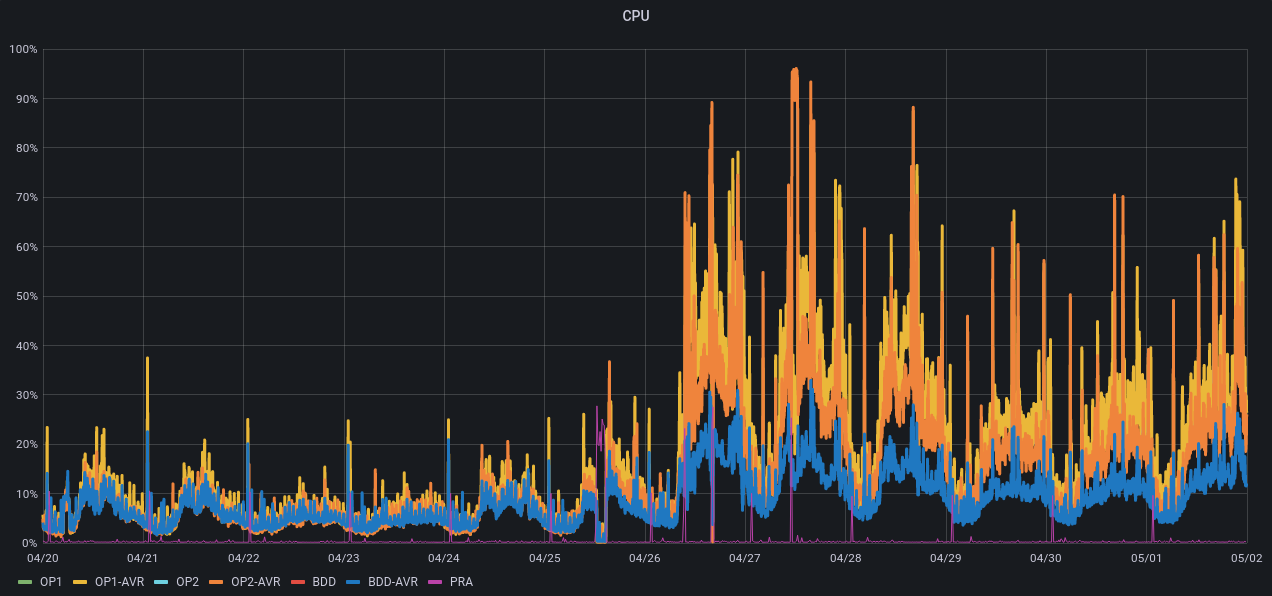
- On constate que le CPU continue de prendr plus cher qu'avant.
- Le.htaccess semble hors de cause
- Un pic Apache/ load vers 16h
Depuis :
- le CPU est toujours pas revenu à la normale
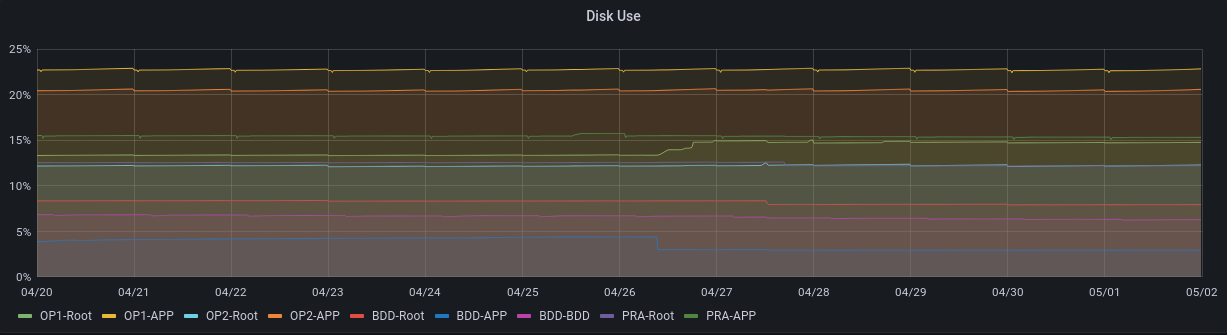
- l'usage disque du CPU n'est pas descendu à son niveau d'avant le 26 avril
- l'usage disque de la BDD est tombé depuis le 26 avril sans remonter
- pour le reste ça semble OK
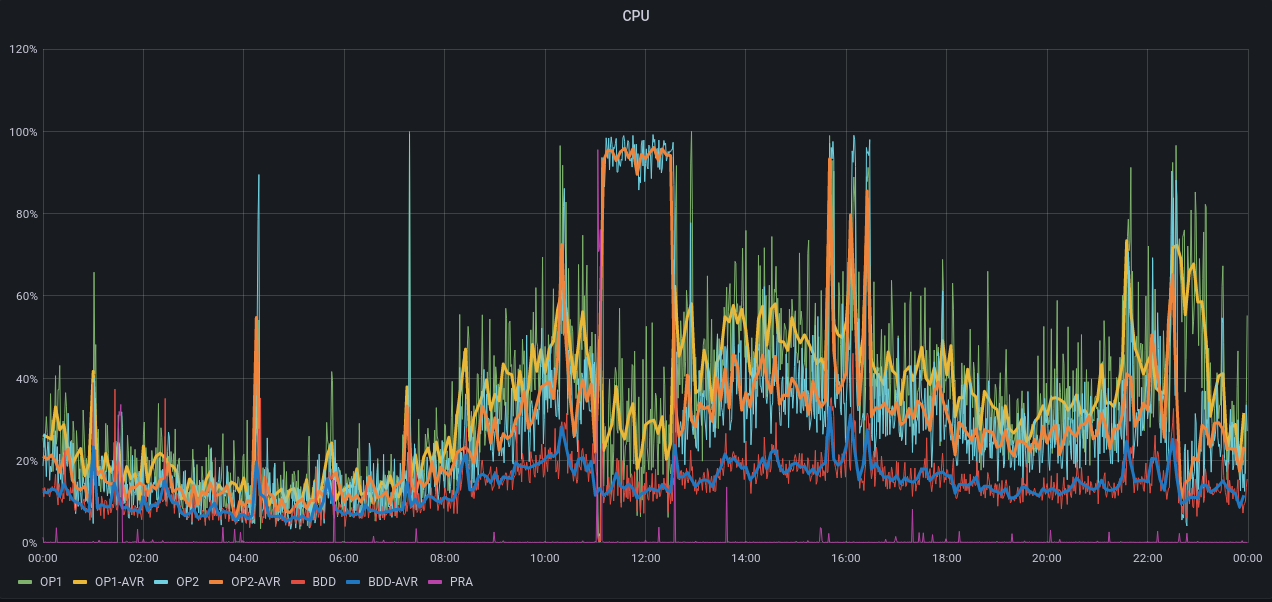
- 5 mai RE-un pic avec effondrement RPS Apache, explosion CPU et RPS Apache CNX, et load
- 9 mai RE-indispo du site
- 9 mai 10h15 Patrice va dans Site Health en BO WP, lance l'action pour corriger un problème SSL
- plus de problème depuis
Fichiers
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Mis à jour par ggallais il y a presque 3 ans
- Fichier SGP_prod_26avril2023_00-24h_cpu.png SGP_prod_26avril2023_00-24h_cpu.png ajouté
- Fichier SGP_prod_26avril2023_00-24h_apache.png SGP_prod_26avril2023_00-24h_apache.png ajouté
- Fichier SGP_prod_26avril2023_00-24h_ApacheCNX.png SGP_prod_26avril2023_00-24h_ApacheCNX.png ajouté
- Fichier SGP_prod_26avril2023_00-24h_load.png SGP_prod_26avril2023_00-24h_load.png ajouté
- Description mis à jour (diff)
Mis à jour par ggallais il y a presque 3 ans
- Fichier SGP_prod_27avril2023_00-24h_cpu.png SGP_prod_27avril2023_00-24h_cpu.png ajouté
- Fichier SGP_prod_27avril2023_00-24h_apache.png SGP_prod_27avril2023_00-24h_apache.png ajouté
- Fichier SGP_prod_27avril2023_00-24h_apacheCNX.png SGP_prod_27avril2023_00-24h_apacheCNX.png ajouté
- Fichier SGP_prod_27avril2023_00-24h_apache.png SGP_prod_27avril2023_00-24h_apache.png ajouté
- Fichier SGP_prod_20avril-2mai_cpu.png SGP_prod_20avril-2mai_cpu.png ajouté
- Sujet changé de Indisponibilité du site à Augmentation de l'usage CPU du site
- Description mis à jour (diff)
Mis à jour par ggallais il y a presque 3 ans
Ah, on voit aussi que l'usage disque tombe puis reste stable pour la BDD le 26 avril... tandis qu'OP1 augmente et reste stable.
Mis à jour par ggallais il y a plus de 2 ans
- Bloque Bug #275: Les liens ancrés génèrent du blanc sur les pages ajouté
Mis à jour par ggallais il y a plus de 2 ans
- Fichier Screenshot 2023-05-05 at 16-26-20 Erreur de la base de données.png Screenshot 2023-05-05 at 16-26-20 Erreur de la base de données.png ajouté
Mis à jour par ggallais il y a plus de 2 ans
- Description mis à jour (diff)
Au-delà de la question technique, la méthode de résolution de la TMA / TMI interroge. Depuis 2 semaines, on a l'impression qu'on saute sur la 1re explication qu'on trouve, sans chercher franchement plus loin, ni démontrer que c'est la bonne.
Quand Google a eu une panne, c'était la panne Google le problème : on a prouvé que c'était faux. Quand on a identifié PHP7.4-FPM comme source de problème, on l'a désactivé : ça n'a pas empêché les problèmes de réapparaître et le CPU de rester sur-utilisé après la désactivation de FPM.
On a l'impression que la 1re idée est toujours la bonne, et surtout que dès que l'incident se calme, on arrête de chercher sa cause... Jusqu'au nouvel incident, on on sort une nouvelle explication du chapeau.
Mis à jour par ggallais il y a plus de 2 ans
- Description mis à jour (diff)
- Statut changé de New à Closed
Je clos le ticket comme résolu. Bilan :
- le problème venait d'une mauvaise config SSL
- la cause est quasi-certainement l'installation / désintallation de RS SSL (= ma faute)
- en 15 jours, ATOS n'a été capable ni d'identifier la cause du problème, ni de résoudre l'incident
- le problème a été résolu par Patrice, par semi-hasard
Conclusion : à quoi sert ATOS ?